Understanding R2

Introduction
I’m working in a playground kaggle competition called Regression with a Flood Prediction Dataset. The goal of the competition is to predict the probability of a flood event in a given region based on a set of features. The submission are evaluated using \(R^2\) score.
A good way to start is to understand the evaluation metric that, in this case, we are going to try to maximize. So what is \(R^2\) score?
You might have heard from school that \(R^2\) measure the proportion of the variance in the dependent variable that is predictable from the independent variable. But what does that mean?
Evaluation metric
An evaluation metric is a way to measure how good your model is. This arise the question: what is a good model? A good model is a model that is able to generalize well. That is, a model that is able to make good predictions on unseen data. A good prediction is a prediction that is close to the true value. In statistics, we define residuals as the difference between the true value and the predicted value from the model.
Residuals
\[y = [y_1, ..., y_n]\] \[ r = [r_1, ..., r_n] = [y_1 - \hat{y}_1, ..., y_n - \hat{y}_n]\] Where \(y\) is the true value, \(\hat{y}\) is the predicted value and \(r\) is the residual.
The sum of the residuals will be zero and there’s a mathematical proof (at the end).
In linear regression, we’re trying to find the best-fitting line that minimizes the distance between the observed data points and the line. The best-fitting line is the one that minimizes the sum of the squared residuals.
The residuals are the differences between the observed values (y) and the predicted values (ŷ) based on the regression line. The mean of the observed values is \(\bar{y} = \frac{1}{n}\sum y_i\).
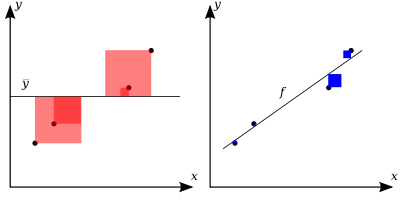
RSS and SST
Once we have the mean, we can calculate the variability of the observed values. We can calculate with two sum of squares. The total sum of squares (SST) is the sum of the squared differences between the observed values and the mean of the observed values, $SST=_i{(y_i-{y})^2} $ (red squares in the plot). So the total sum of squares is proportional to the variance of the observed values.
The residual sum of squares (RSS) is the sum of the squared differences between the observed values and the predicted values, \(SSR = \sum{(y_i - f_i)^2} = \sum_i{e_i^2}\) (blue squares in the plot).
SSR/SST is the fraction of variance unexplained. The fraction of variance explained is \(R^2 = 1 - SSR/SST\).
The best model posible will be one with SSR = 0 and the R2 score will be 1. So R2 score measure goodness of fit.
Values outside the range [0,1] are possible when the model is worse than the mean model, the SSR is greater than the SST, and the R2 score is negative.
Adjusted R2
The R2 score has a problem. It increases as we add more features to the model. This is because the model will always explain more variance with more features. The adjusted R2 score is a modified version of the R2 score that has been adjusted for the number of features in the model. The adjusted R2 score is calculated as:
\[R^2_{adj} = 1 - \frac{(1 - R^2)(n - 1)}{n - k - 1}\]
where n is the number of observations and k is the number of features in the model. The adjusted R2 score will be less than the R2 score when the number of features is greater than 1.
Or from the definition of R2 we can write the adjusted R2 as:
\[R^2_{adj} = 1 - \frac{SSR/(n-k-1)}{SST/(n-1)}\]
where n is the number of observations and k is the number of features in the model. We basically divide the SSR and SST by the degrees of freedom, define as the number of observations minus the number of parameters in the model.
Proof that the sum of the residuals is zero
The OLS method estimates the regression coefficients (β) by minimizing the sum of the squared residuals (SSR). The SSR is calculated as: \[SSR = \sum (y - \hat{y})^2\] where y is the observed value, ŷ is the predicted value, and the sum is taken over all data points.
When we minimize the SSR, we’re essentially finding the regression line that passes through the mean of the data points. Imagine a regression line that doesn’t pass through the mean of the data points. In this case, the residuals would not sum to zero, as the line would be biased upwards or downwards. By minimizing the SSR, we’re forcing the regression line to pass through the mean of the data points, which means that the sum of the residuals must be zero.
Proof:
Let’s denote \(e = y- \hat{y}\), we want to show that \(\sum e = 0\).
We know that \(\hat{y} = \beta_0 + \beta_1x\)
Using the definition of \(\hat{y}\), \(e = y - \beta_0 - \beta_1x\).
Taking the sum of both sides we have: \[\sum e = \sum y - \sum \left(\beta_0 - \beta_1x\right)\] \[\sum e = \sum y - n\beta_0 - \beta_1\sum x\] where n is the number of observations.
Recall that the OLS estimates of β0 and β1 are chosen to minimize the SSR. This means that the following conditions must be satisfied.
\[\frac{\partial SSR}{\partial \beta_0} = -2\sum (y - (\beta_0 + \beta_1 x)) = 0\] \[\frac{\partial SSR}{\partial \beta_1} = -2\sum x(y - (\beta_0 + \beta_1 x)) = 0\]
Simplyfing the first and second equation we have: \[\sum y = n\beta_0 + \beta_1\sum x\] \[\sum xy = \beta_0\sum x + \beta_1\sum x^2\]
Substituting the first equation into the expresion \(\sum e = \sum y - \sum \left(\beta_0 - \beta_1x\right)\) we have: \[\sum e = 0\]