Quarto draft document, one-hot encoding or label encoding, transforming the target variable

Daily Note - 21/05/2024
1. Mark the document as a draft in Quarto
You can control whether a document is published by setting its draft status. When a document is marked as a draft, it won’t be included in the published output.
Add the following YAML metadata at the beginning of the document:
---
draft: true
---2. The choice between one-hot encoding and label encoding
If the categories are nominal (no natural order), one-hot encoding is usually preferred. This ensures that the model does not infer any ordinal relationship between the categories. Also, One-hot encoding is more feasible when the categorical variable has a relatively small number of unique categories.
If the categories have a meaningful order (e.g., low, medium, high), label encoding can capture this ordinal relationship. The numerical labels assigned by label encoding can reflect this order.
Caveats:
Some algorithms, like tree-based models, can handle label encoding even if the categories are not ordinal because these models are not sensitive to the numerical order of labels. However, for linear models or distance-based algorithms (e.g., k-nearest neighbors, SVMs), label encoding can introduce misleading relationships between categories
3. Whether or not to transform a target variable
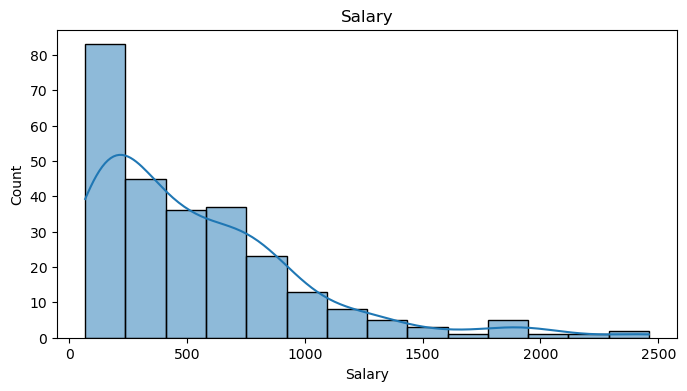
First assess the distribution of the data and understand why a transformation might be beneficial.
Many statistical models assume that the residuals (errors) of the model are normally distributed. If your target variable is highly skewed, as the salary distribution, a transformation might help to achieve normality.
Homoscedasticity refers to the assumption that the variance of the residuals is constant across all levels of the independent variables. A skewed predictor or target variable can lead to heteroscedasticity, which can violate this assumption. Transforming the target variable can help stabilize the variance.
A skewed distribution often indicates the presence of outliers, which can disproportionately influence the model. Transforming the data can reduce the impact of these outliers.